Predicting spoilage
Predictive modeling has emerged as a powerful tool in food and cosmetic microbiology, transforming the way researchers anticipate and control product spoilage. Traditionally, shelf-life determinations depended on time-consuming, empirical stability studies, limiting the ability to optimize formulations. These inefficiencies can drive either conservative estimates, causing product waste, or optimistic assumptions which can risk quality and food safety.
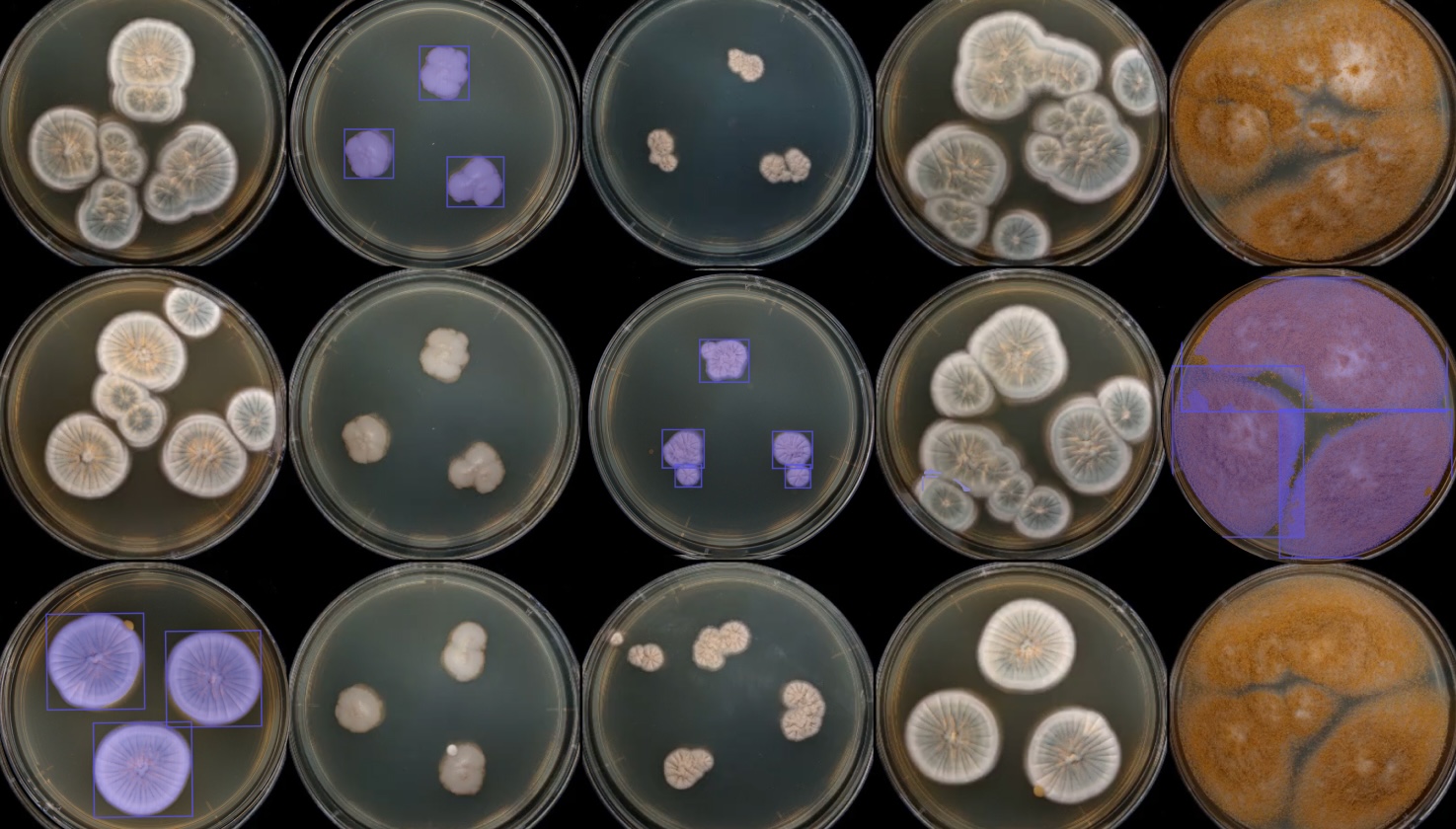
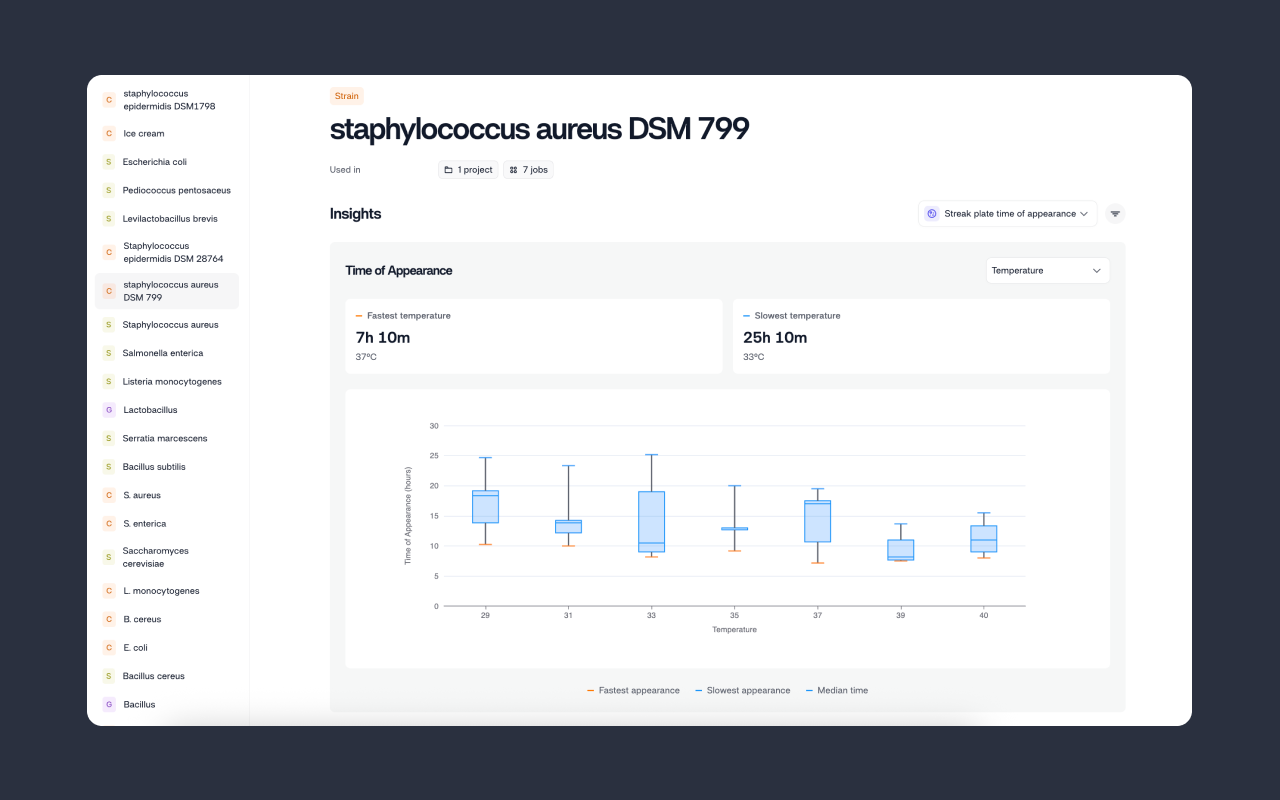
By systematically analyzing the interplay of a wide range of key factors—including pH, water activity, temperature, humidity, and oxygen levels—models can project how quickly microorganisms might grow and, ultimately, when a product is likely to spoil.
These spoilage factors operate in a complex web of interactions. For instance, temperature fluctuations can accelerate microbial activity, but the effect is moderated by other parameters like pH, which may inhibit certain microbial strains. High water activity fosters bacterial and fungal growth, yet low oxygen environments or certain preservatives can significantly slow that growth. Even subtle shifts in packaging integrity—such as minute oxygen ingress—can nudge microbial populations toward a tipping point, turning an otherwise stable product into a quality-control liability.
Including the dynamic nature of real-world conditions is essential. Humidity levels in transport or storage can spike unexpectedly, and temperature control can vary from warehouse to retail shelf. A strong predictive model takes these variations into account, harnessing either historical data or real-time sensor outputs to deliver a continuous estimate of microbial risk. This helps R&D teams proactively adjust formulations, packaging, or distribution methods before problems arise.
Ultimately, the value of predictive modeling lies in its ability to integrate complex and diverse conditions, capture non-linear interactions, and create actionable insights. In a market that demands both high cost efficiency and uncompromising quality, these models will grow in importance to drive innovation, risk management, and sustainable product development.
Predictive model engineering
Predictive modeling spans a spectrum of techniques, ranging from simpler statistical regressions to advanced deep learning architectures. Traditional models—such as polynomial or exponential regressions—have the benefit of simplicity and interpretability. They can capture fundamental microbial growth curves reasonably well, especially when the data size is small or highly controlled. However, they often struggle with more complex, real-world dynamics where interactions between temperature, moisture, and packaging materials are highly non-linear.
Enter modern machine learning and time-series deep learning methods like recurrent neural networks (RNNs) and Transformers. These models are adept at processing sequential data and can handle the variability of real-world conditions more gracefully. By learning from historical measurements (e.g., temperature or humidity changes over time), they can generate more accurate predictions of microbial behavior. The downside is that these models often require larger datasets and careful tuning. Domain-specific knowledge—such as understanding which spoilage organisms are most relevant for a given product—helps improve accuracy and reduce the risk of overfitting.
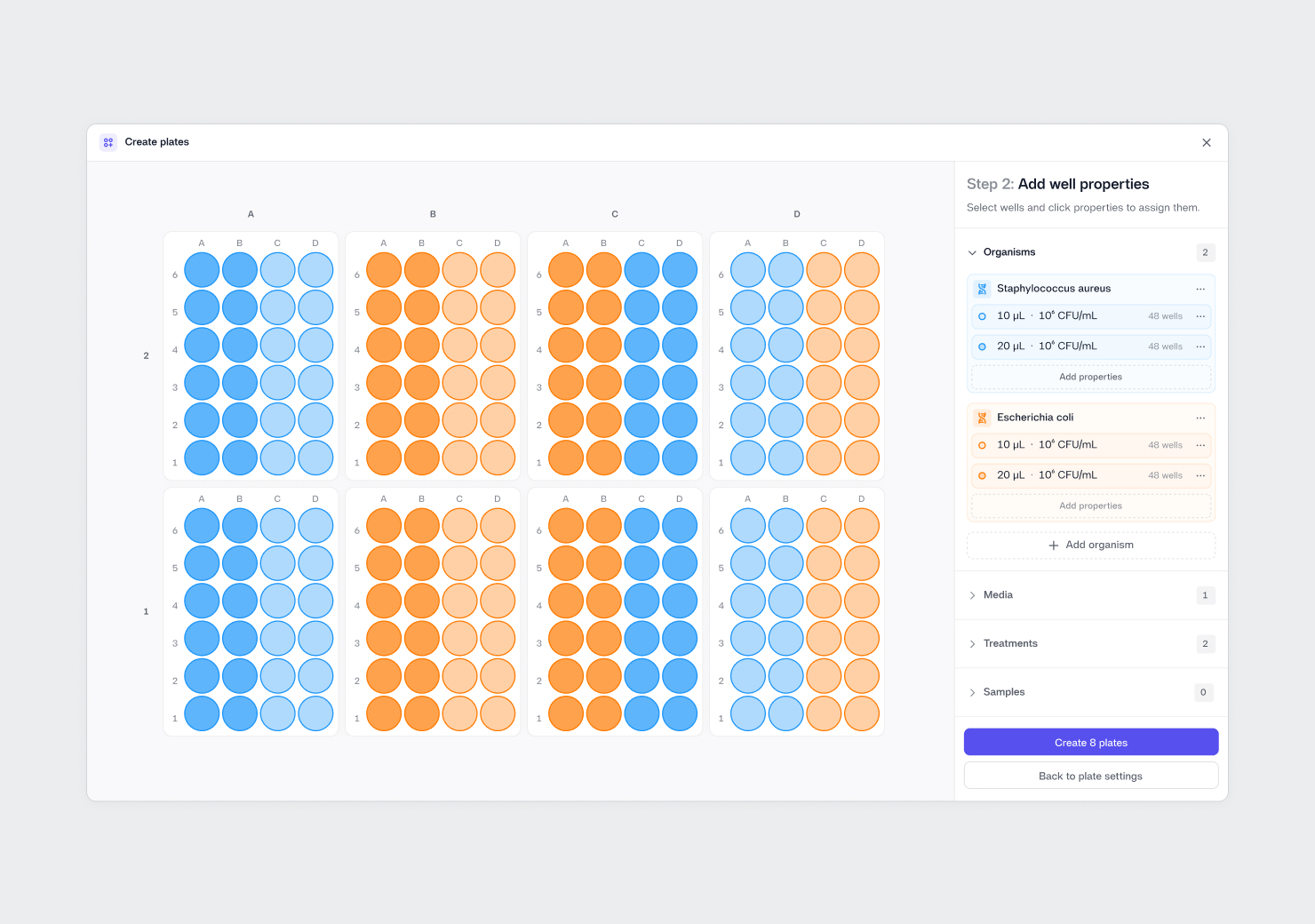
Data quality and availability are the cornerstones of successful modeling. In practice, companies need to gather reliable in-vitro measurements (e.g., microbial growth in a controlled petri dish) and in-vivo data (e.g., actual spoilage in packaged goods). Ensuring consistency in how measurements are collected, stored, and labeled is key. Metadata—covering everything from batch information and production timestamps to packaging details—can greatly enhance model performance. Additionally, incorporating real-time sensor inputs (like temperature loggers in shipping containers) can keep the model updated with the latest conditions, providing dynamic rather than static predictions. In short, the strength of any predictive model is determined not just by its algorithmic sophistication, but also by the depth, breadth, and accuracy of the data feeding it.
Impact
Predictive modeling has immense applications across the product life cycle, from concept to market. During research and development, these models streamline shelf-life testing by pinpointing formulations that are more or less prone to microbial growth under varying conditions. By simulating outcomes digitally, teams can quickly decide whether to incorporate additional preservatives or adjust packaging configurations before conducting extensive physical tests. Think of it as an additional layer of an R&D funnel - instead of jumping straight to designing campaigns and experiments for a new project based on scientific expertise, the first step will become simulating a large range of parameters and using this to dramatically narrow down the relevant search space before starting to conduct experiments.