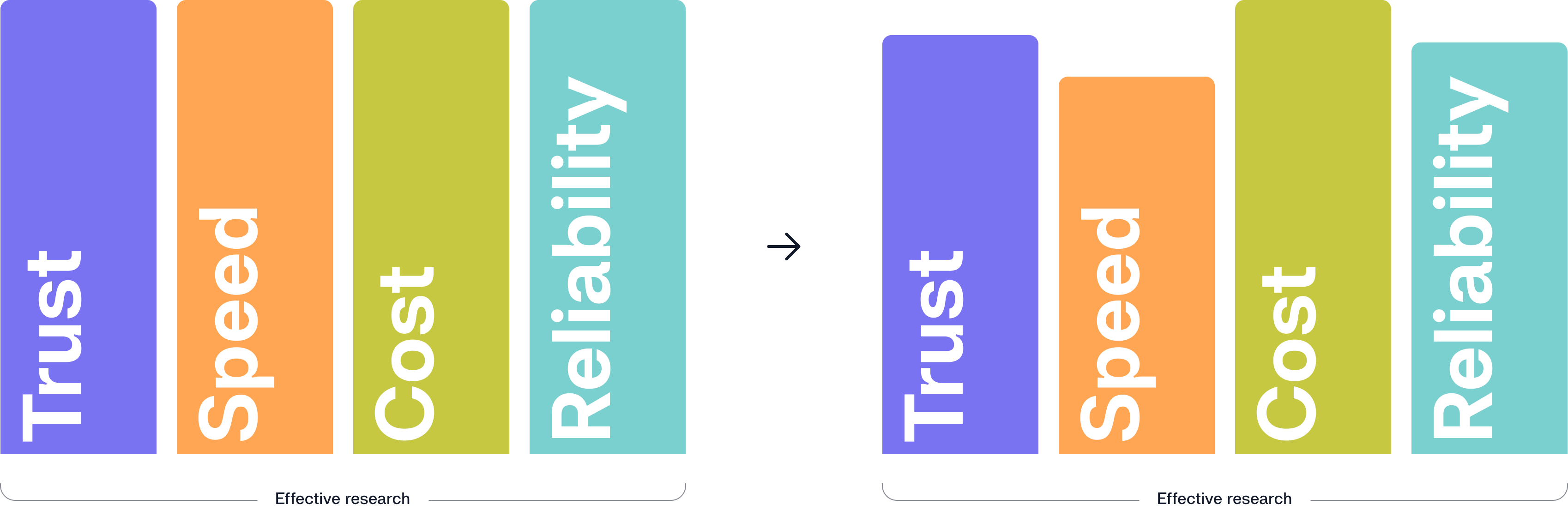
What do I mean by effective research? I am referring to how we uphold the pillars of trust, speed, cost efficiency and reliability. These pillars are essential, but the emphasis on each one naturally shifts over time. Labs often try to protect these pillars by generating robust standard operating procedures (SOPs), investing in training to maintain good lab practices, or implementing a lab management system (LIMS). These efforts matter, but I want to make the case for automation and AI.
Apart from the rise of the world wide web and instant access to information, I do not think we have lived through a more exciting time in research than the age of AI. AI is emerging at a moment when the world faces increasing sustainability demands and climate pressures, yet the market standard still shows that it can take up to (US)300 million dollars and 12 years to bring a new product to market. This is alarming, because we know the world urgently needs better solutions, and it needs them much faster. There appears to be a widening gap between the urgency of global problems and the speed at which we can respond with new technologies.
Although major factors like funding models, pressure to scale too soon, regulatory hurdles. or misaligned incentives play a role, one often overlooked barrier is how data is acquired inside the lab.
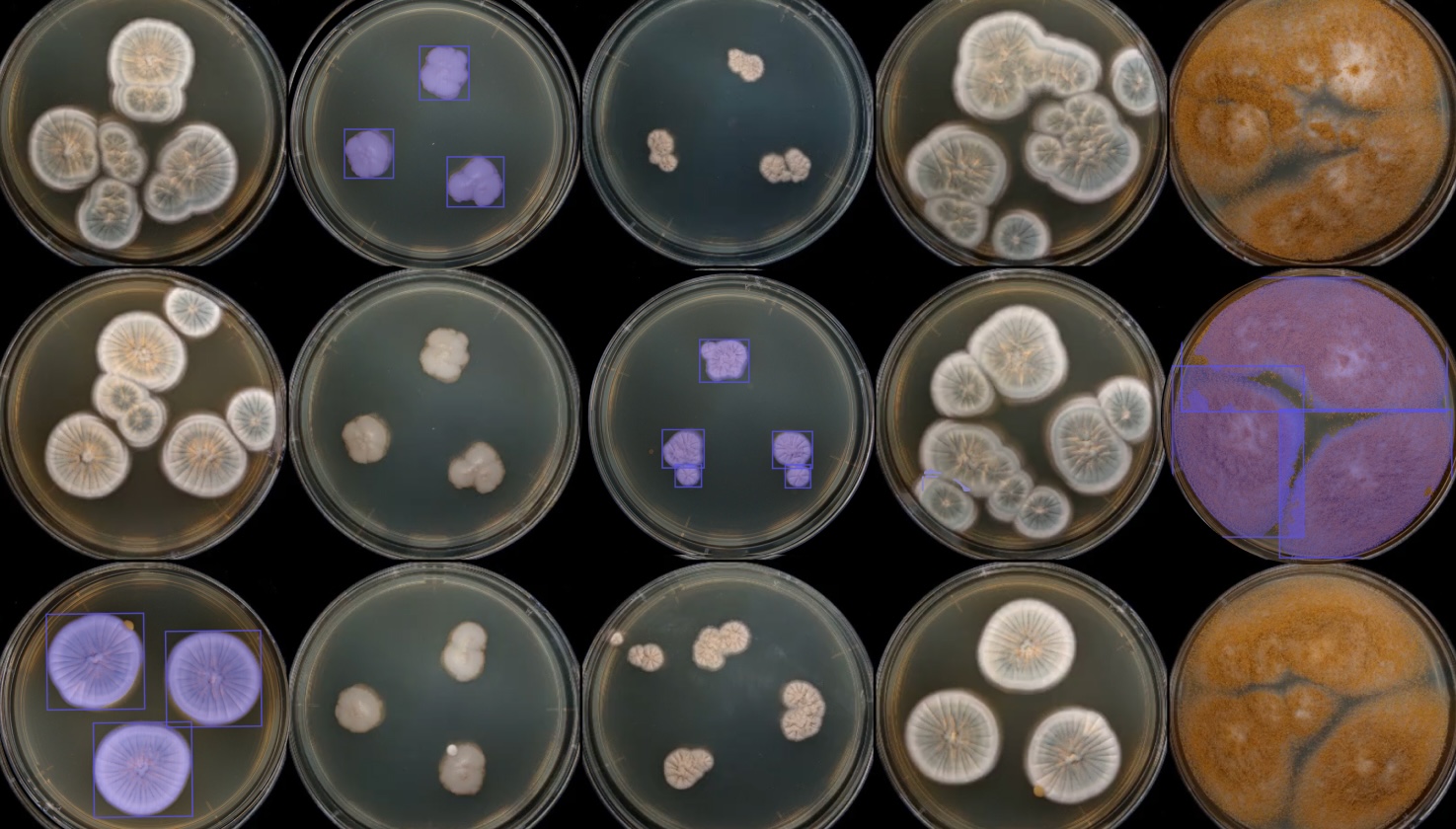
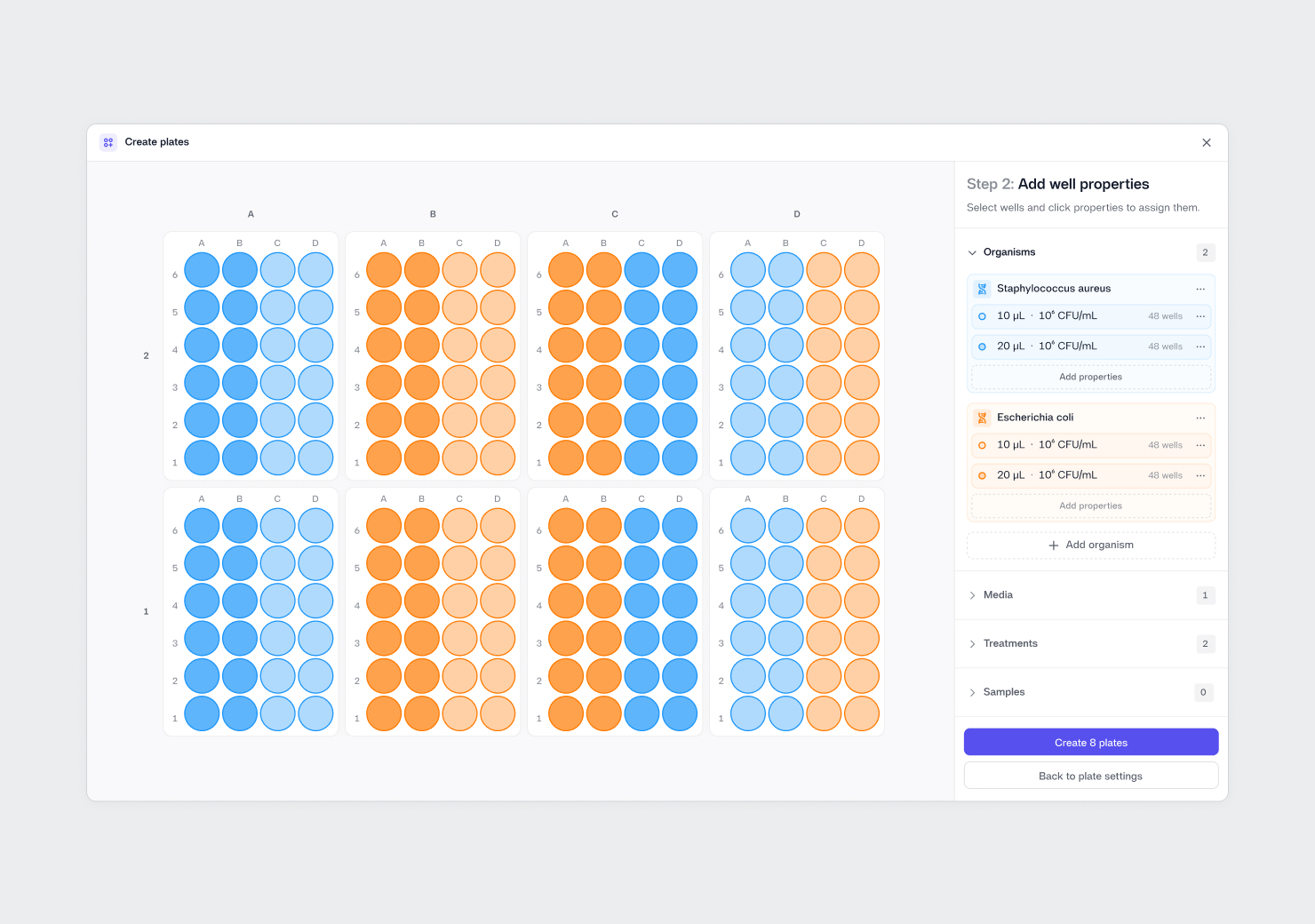
At Reshape, we have learned this by working alongside in-house scientists and by spending nearly a decade listening to lab managers, R&D leaders, innovation teams and CTOs. Continuously, we find that the most common factors holding labs back stems from outdated tools. Research is still an artisanal and manual process. Human gathered data is prone to error and often subjective. Biology itself is complex, yet we try to fit it into a nine to five schedule when we should be collecting data around the clock. On top of that, we work with unstructured data, which makes it difficult to learn quickly or confidently from experiments.
If you have worked in a lab, you know that knowledge is everywhere and somehow also nowhere. In seasonal workflows, scientists might run several projects and spend the rest of the year trying to sort and interpret the data. Information ends up scattered across spreadsheets, Google Drive folders, instruments and of course people. This results in a fragile data foundation. The knowledge exists, and the money and time have been spent, but the output is not easily accessible or scalable.
We have also fallen into a pattern where the default solution for scaling research while trying to protect the pillars of effective research is to add more people, buy more tools, or add more rules. But when you scale a team from five to twenty-five, inefficiencies multiply. Collaboration gaps widen, data becomes messy and decision making slows down. More smart people does not automatically mean more productivity. This is the shift we need to make. We need to scale efficiently.

The reality is that even as we try to protect trust, speed, cost efficiency and reliability, the world demands solutions much faster than our traditional methods can deliver. Meeting those demands requires more than improving old processes. It requires reshaping how research is done. That includes rethinking how we design workflows, how we capture and structure data, and how we use automation and AI as foundational tools.
We have already seen what this type of thinking can achieve in biology. A clear example is AlphaFold from Google DeepMind, which solved one of the hardest challenges in biology: accurately predicting the 3D structure of proteins from their amino acid sequences. Before AlphaFold, we had around 170,000 experimentally determined protein structures in public databases. In just four years, AI and predictive modeling increased that number to nearly 200 million. A process that was slow and incremental suddenly became scalable. This is the type of step change we need in lab workflows. Not just marginal improvements, but a complete shift in the scale and speed at which effective research can happen while still protecting trust, reliability and cost efficiency.
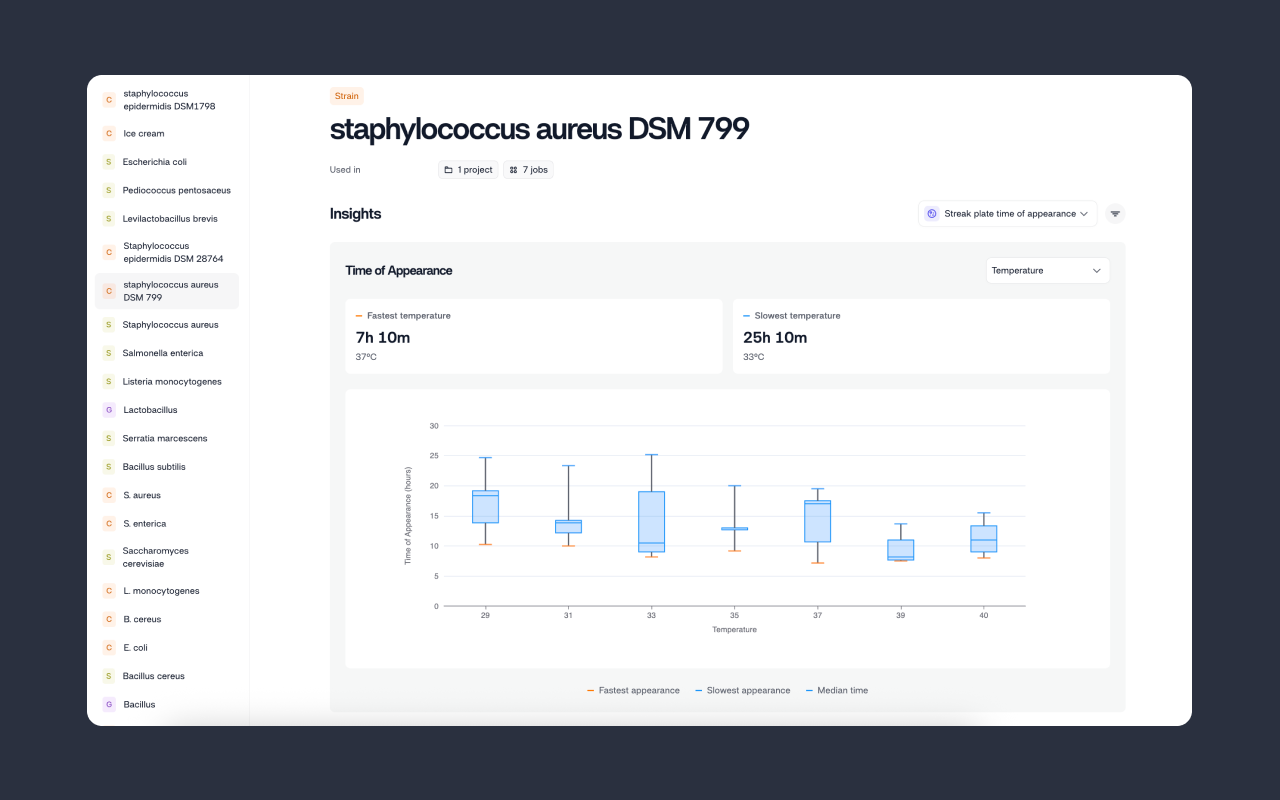
In practice, this shift means moving from human, error prone, subjective data collection to a more accurate, objective and reproducible approach powered by automation, computer vision and machine learning. Continuous and standardized data collection builds a strong foundation for downstream analytics. When data becomes structured, contextualized and easily searchable, collaboration becomes simpler. Repeated experiments decrease, waste is reduced, and decisions can be made much faster.
We are also riding an AI wave where leadership teams are asking how to adopt AI tools and maintain competitiveness.
This has revealed a core truth. AI requires strong data foundations to work effectively.
This is one reason why LIMS adoption is increasing. However, most LIMS platforms still rely on manual inputs pulled from notebooks, spreadsheets and human generated assay data, which, as I have emphasized repeatedly, is error prone. The top down approach needs to be reversed. Instead of adding AI on top of messy data, we need automated and AI assisted data acquisition to feed directly into LIMS systems so that downstream analytics can be built on clean and reliable information. When we transition from human dependent to human plus AI workflows, productivity scales exponentially instead of plateauing.
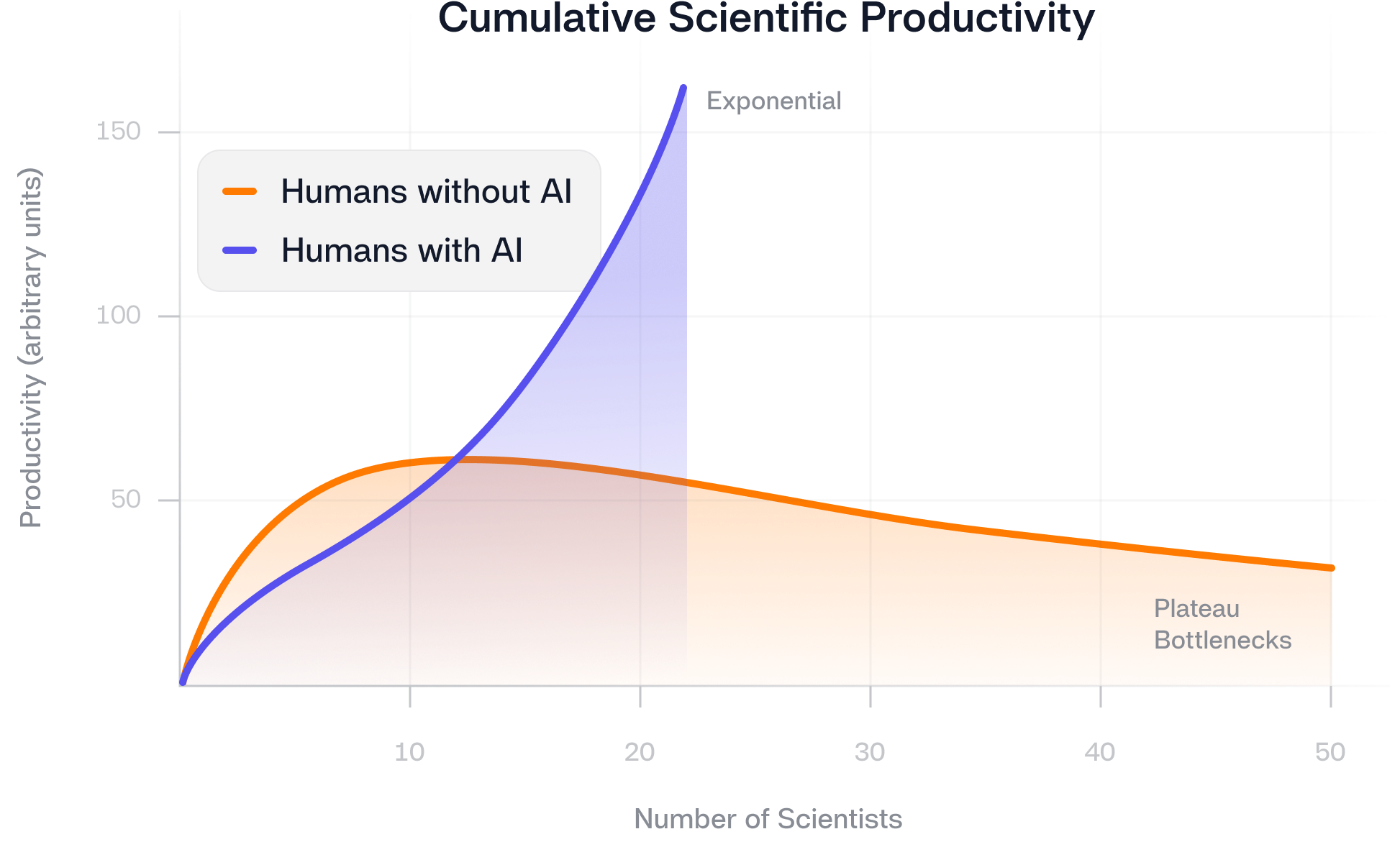
To answer my original question, yes, we can scale and produce effective research while protecting all four pillars equally. This becomes far more achievable when we embrace automation and AI in our lab workflows. This is how we move from isolated wins to truly effective and scalable research.